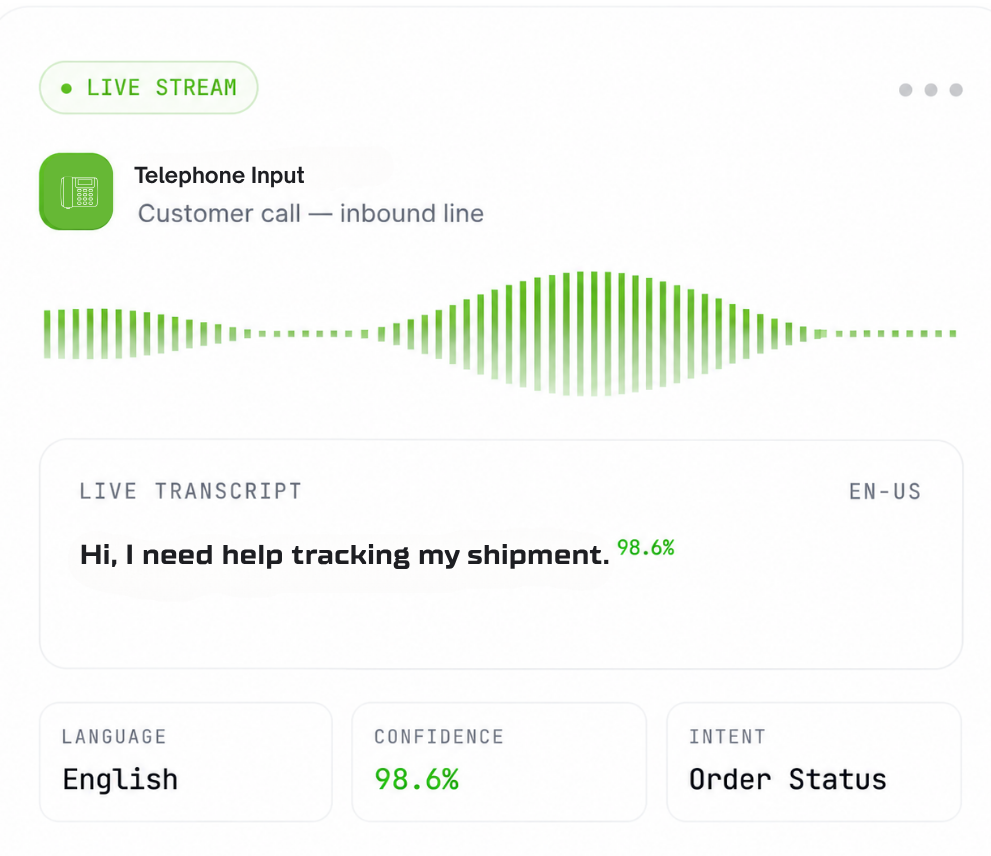
Listener – AI Speech-to-Text for Real-Time Conversations
Transform Speech into Actionable Intelligence
Listener is GoVivace's enterprise-grade patented Speech-to-Text (STT) engine designed for conversational AI, contact centers, transcription workflows, and multilingual customer interactions.
Built for real-time and batch processing, Listener delivers accurate transcription across voice calls, mobile applications, web applications, and enterprise communication systems. Based on the current product description, it supports streaming and offline transcription, custom vocabularies, multilingual speech recognition, and scalable deployment models.
Why Listener
Supported Languages
Built for Global Conversations
Listener supports the languages your customers speak across the world
01
Real-Time Speech Recognition
Convert live conversations into searchable text with ultra-low latency, so agents and AI systems act while the conversation is still happening.
02
Enterprise Accuracy
Improve transcription with custom vocabularies, business terminology, proper nouns, acronyms, and domain-specific language your teams actually use.
03
Multilingual Recognition
Support global and regional languages with seamless multilingual recognition and natural code-switching between them.
04
Cloud, On-Premise & Hybrid
Deploy securely in cloud, on-premise, or hybrid environments to meet enterprise security, data residency, and compliance requirements.
English EN
Spanish ES
French FR
German DE
Italian IT
Portuguese PT
Mandarin ZH
Arabic AR
Vietnamese VI
Japanese JA
Hindi HI
Tamil TA
Telugu TE
Kannada KN
Malayalam ML
Marathi MR
Gujarati GU
Bengali BN
Odia OR
Assamese AS
Code-Switching Support
Listener can recognize mixed-language conversations
The current Listener platform already emphasizes multilingual and code-switching capabilities, especially for multi-lingual markets.
Transcript ● Live
Transcript
Hola, I placed an order yesterday, pero todavía no recibí la confirmación. Can you please check it?
Languages Detected
English + Spanish
Language Identification
Spanish 35.3%
English 64.7%
Extracted Keywords
order
confirmación
placed
check
AI Insights
Order Status Inquiry
Topic
E-commerce Customer Support
Sentiment
Neutral → Mild Concern
Transcript Metadata
Number of Speakers 1
Confidence 98.1%
Duration 6.12 sec
Words 17
Punctuation 4
Languages 2
Code-switch 3
Latency <300ms
98.1%
Overall Confidence
Word Alignment
Hola
99.6%
0.09 - 0.37
I
99.8%
0.50 - 0.58
placed
99.5%
0.59 - 0.88
an
99.6%
0.89 - 0.98
order
99.7%
0.99 - 1.29
yesterday
99.4%
1.30 - 1.74
pero
99.2%
1.92 - 2.08
todavía
98.9%
2.09 - 2.47
no
99.1%
2.48 - 2.59
recibí
98.7%
2.60 - 2.98
la
99.2%
2.99 - 3.11
confirmación
98.8%
3.12 - 3.72
Can
99.6%
4.02 - 4.20
you
99.5%
4.21 - 4.38
please
99.7%
4.39 - 4.73
check
99.4%
4.74 - 5.04
it
99.5%
5.05 - 5.18
Language Mix Timeline
Transcript ● Live
Transcript
Hi, मेरा internet connection कल से बहुत slow है । Can you please check my account?
Transliterated
Hi, mera internet connection kal se bahut slow hai. Can you please check my account?
Language Identification
Hindi 46.2%
English 53.8%
Extracted Keywords
internet
connection
slow
account
AI Insights
Technical Support
Topic
Internet Connectivity
Transcript Metadata
Number of Speakers 1
Confidence 97.8%
Duration 5.84 sec
Words 15
Punctuation 3
Languages 2
Code-switch 5
Latency <300ms
97.8%
Overall Confidence
Word Alignment
Hi
99.8%
0.08 - 0.28
मेरा
98.7%
0.33 - 0.60
internet
99.5%
0.61 - 0.94
connection
99.2%
0.95 - 1.39
कल
98.6%
1.46 - 1.63
से
98.4%
1.64 - 1.76
बहुत
97.9%
1.77 - 2.05
slow
99.1%
2.07 - 2.36
है
98.2%
2.38 - 2.55
Can
99.6%
3.02 - 3.23
you
99.4%
3.24 - 3.40
please
99.7%
3.42 - 3.73
check
99.5%
3.74 - 4.05
my
99.6%
4.06 - 4.18
account
99.4%
4.19 - 4.76
Language Mix Timeline
Key Features
Enterprise Speech Intelligence Engine
01
Streaming Speech Recognition
+
Low-latency transcription for live voice streams and continuous recognition—the backbone of real-time AI workflows and agent assist.
Low-latency
Live Streams
Continuous Recognition
Real-time AI
02
Batch Transcription
+
Process meeting recordings, call archives and media libraries accurately at scale.
Meetings
Call Archives
Bulk Audio
Media Files
03
Custom Vocabulary Adaptation
+
Improve recognition with product names, acronyms, medical and financial terminology.
Industry Terms
Medical
Financial
Proper Nouns
04
Keyword Spotting
+
Detect compliance triggers, customer intent and business-critical keywords automatically.
Compliance
Intent
Keywords
05
Hint Word Recognition
+
Boost transcription accuracy using expected words and phrases.
Hint Words
Accuracy
Structured Calls
06
Unlimited Audio Processing
+
Handle audio streams of any duration.
07
API & SDK Integration
+
REST APIs, WebSocket APIs, SDKs and enterprise integration support.
REST API
WebSocket
SDK
MRCPv2
Authentication
Industry Use Cases
Built for every industry
Contact Centers
- Call transcription
- Agent assistance
- Quality monitoring
Conversational AI
- Voice bots
- AI assistants
- Conversational IVR
Banking & Financial Services
- Customer authentication workflows
- Call documentation
- Compliance monitoring
Healthcare
- Medical dictation
- Appointment interactions
- Clinical documentation
Government & Public Sector
- Citizen services
- Multilingual interactions
- Voice-based access channels
Media & Content
- Captioning
- Subtitling
- Meeting transcription
Enterprise Capabilities
Why Enterprises Choose Listener
Real-Time Streaming
Active
Batch Transcription
Active
Custom Vocabulary
Active
Keyword Spotting
Active
Hint Words
Active
Multilingual Recognition
Active
Code Switching
Active
Cloud Deployment
Active
On-Premise Deployment
Active
Hybrid Deployment
Active
API Integration
Active
MRCPv2 Support
Active
GoVivace Voice AI Ecosystem
Part of the GoVivace Voice AI Ecosystem
L
Listener
Understands Speech
A
Authenti
Verifies Identity
E
Eloqui
Speaks Naturally
C
CallAI
Extracts Intelligence
V
VIVI
Enterprise AI Agent
FAQ —
Frequently Asked Questions
Speech-to-Text converts spoken language into written text for search, automation, analytics, and conversational AI applications.
Listener supports English, Spanish, French, Italian, German, Portuguese, Mandarin, Arabic, Vietnamese, and multiple Indian languages including Hindi, Tamil, Telugu, Malayalam, Kannada, Marathi, Gujarati, Odia, Bengali, and Assamese.
Yes. Listener supports both streaming and batch transcription workflows.
Yes. Custom vocabulary adaptation allows Listener to improve recognition of domain-specific words and phrases.
Yes. Listener can be deployed in cloud, on-premise, or hybrid environments.
Yes. Listener supports multilingual speech recognition and code-switched conversations.
Turn every voice interaction into business intelligence
Discover how Listener enables enterprises to transcribe, understand, automate, and optimize every customer conversation with enterprise-grade speech intelligence.